
- Founded in 2004
- Focus on filmmakers and high-quality content
- Lots of website embeds
- Here in NYC!

- Hiring!
Skyfire
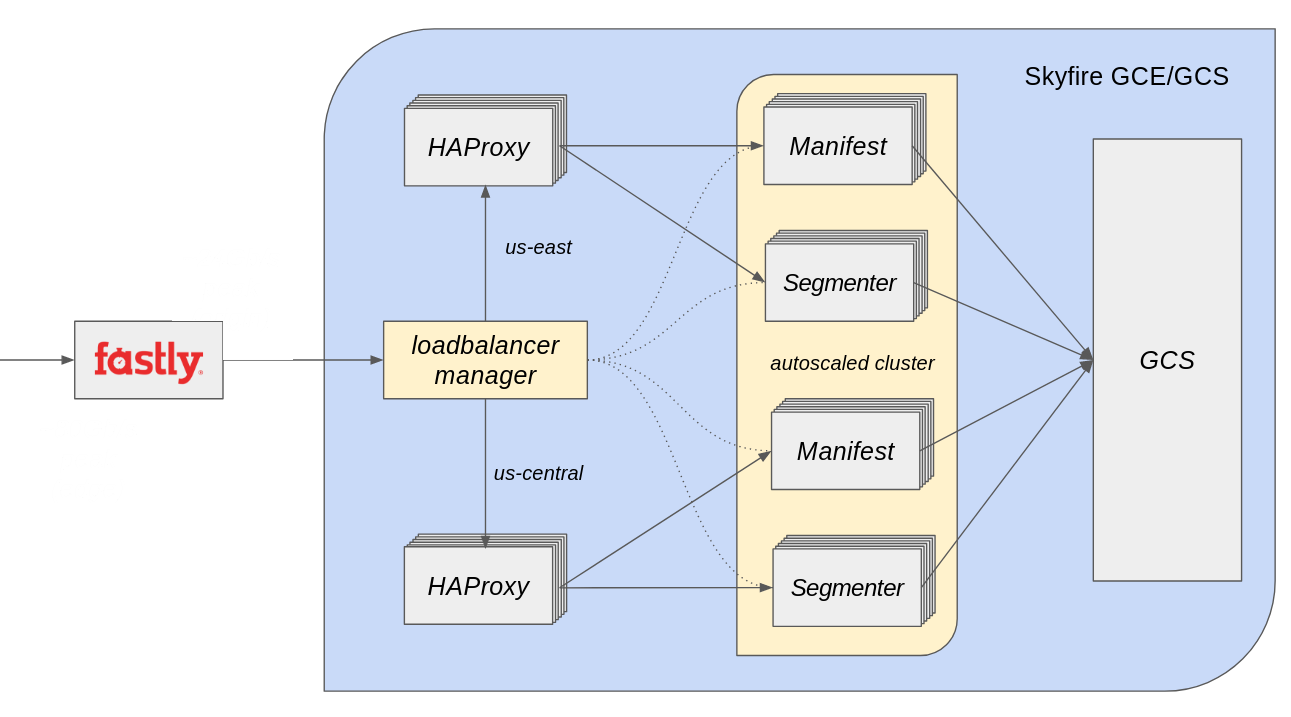
- Skyfire is our dynamic video packager
- Serves playlists and video segments for DASH and HLS
- Runs in the cloud
- HAProxy load balancer
Handles the majority of our website plays, and all iOS/Android; gets over 1 billion requests/day
Skyfire (deployment diagram)
Dynamic Packaging
- Decades of content stored as progressive MP4
- Need to serve it as fragmented MP4 or TS for DASH/HLS
- Remuxing everything would be a huge effort
- Do it on demand instead (in-house technology, libchopshop)
Indexing
- Transmuxing is not too hard, but we need an index to allow random access
- Contains locations of all of the keyframes and all of the A/V packets in the file
- Generating requires a couple HTTP requests and a bunch of CPU
- We get multiple requests for a video, so we should cache the index
First Approach
(Launch through Nov 2015)
- Cache indexes in memory on each machine
- Use consistent hashing to send requests to the machine with the data
Hash Review: Modulo Hashing
- Hash part of the request to choose the server
server_id = hash(request) % num_servers- Disturbs the majority of the hash space on adding or removing a server
Consistent Hashing
- Algorithm invented in 1997
- Hash part of the request to choose the server
- Also hash several versions of a persistent server ID
- Choose the server with hash nearest to the request hash
- More stable across server adds/deletes
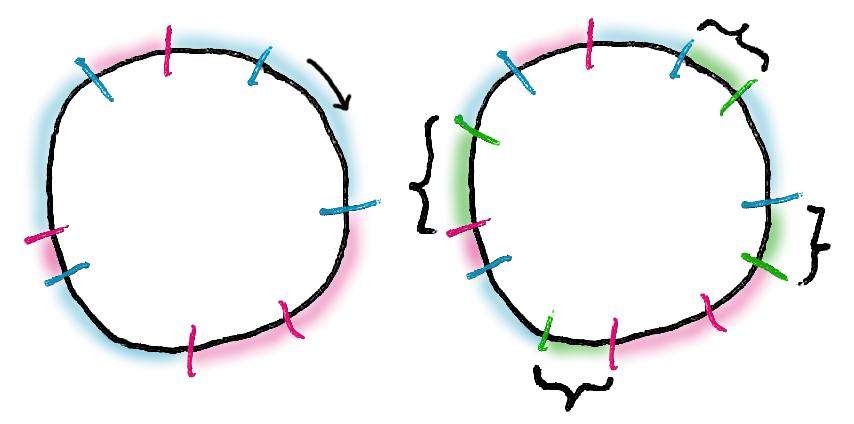
(Image courtesy Zack M. Davis)
Hash space is treated like a ring. When a new server is added, it adds several points to the ring.
Some parts of the ring will now be closest to the new points, so a portion of traffic moves to the new
server. But most parts stay the same. Likewise for deletion.
Problem: Load Distribution
- Consistent hashing doesn’t distribute load very evenly
- (in fact, it’s about as good as randomly assigning requests to servers)
- Plus, some clips can just get an exceptional amount of traffic
- Some servers get overloaded, which hurts user performance
Solution: Different Load Balancing Policy
- Round-Robin: equal requests per server
- Least-Conn: least busy server gets the request
- most equal load, in theory
Problem: Now our cache is no good!
- Without hashing, requests won’t go where the data is already cached
- Cache is effectively useless
- More cost, less performance
Solution: Add a shared cache
- Servers keep local cache, but also fall back to a regional shared cache
- On write: send to both in-memory cache and regional memcached
- On read:
- Check local cache
- If found, issue a “touch” to memcached, and return the value
- If not found, check memcached
- If found, write the data into local cache to reduce the chance of having to fetch it again
Shared Cache Pitfalls
- Works, but…
- Scales poorly: shared cache traffic goes up with # of skyfire servers
- Not fault tolerant: if memcached goes down, our performance is gone
- This is a cache locality problem: any server can handle a request, but some can do it more cheaply
The more servers we have, the lower the chance that a request goes to a server that
already has the data in local cache, so the memcache traffic goes up linearly
(or worse). If memcache goes down, then the situation on the previous slide
dominates.
Wouldn’t it be nice to have both?
- Back in Oct 2015 I tried to come up with an algorithm based on The Power of Two Choices
- I wrote a simulation in Go based on some assumptions on how traffic was distributed and how servers behaved under load
- The simulation said my algorithm was worse than plain consistent hashing or a least-connection policy
- So I gave up and focused efforts on making the shared cache efficient
Brief summary of Power of Two Choices: when you need to make an optimal choice for load balancing, LRU, etc., picking
two random entries and then selecting the better one according to whatever criterion, is almost as good as picking the
globally optimal one, and sometimes even better.
Someone else had more follow-through
- August 2016: Consistent Hashing with Bounded Loads by Mirrokni, Thorup, Zadimoghaddam
- Vahab Mirrokni and Morteza Zadimoghaddam are Google NYC researchers, Thorup was a visiting researcher from Copenhagen
- Damian Gryski posts interesting research papers on Twitter, I found it there.
- Intended for a slightly different use, but that just means I could afford to ignore 2/3 of the paper.
The paper considers hashing for storage, where it’s important to move items to maintain balance after deletions.
I can’t move HTTP connections, only assign them when they come in, so I can ignore these concerns.
The Algorithm in Short
- Compute the average # of requests per server
- Add some overhead, say 25%
- Round up to get the max # of requests per server
- If the chosen server is below the max, send the request there
- Otherwise, go around the hash ring (forwarding) until one is below the max
The paper says “While the idea seems pretty obvious, it appears to not have been considered before.”
Bringing it to Life
- I added a simplified version of the algorithm into my simulator
- Unlike my own algorithm, it actually seemed to perform well
- So I set about adding it into our production load balancer, HAProxy
HAProxy Impelementation
- Written in C
- Neat & well-organized code
- Already has consistent hashing backed by a binary tree
- Adding the bounded load criterion wasn’t too hard
8 files changed, 59 insertions(+), 1 deletion(-)
Challenges
- Do it all with integer math!
- HAProxy doesn’t use any floating-point, and I didn’t want to introduce any
- Support server weighting
- HAProxy allows assigning each server a different fraction of the load
Hash Table Lookup
next = eb32_lookup_ge(root, hash);
if (!next)
next = eb32_first(root);
if (!next)
return NULL;
prev = eb32_prev(next);
if (!prev)
prev = eb32_last(root);
nsrv = eb32_entry(next, struct tree_occ, node)->server;
psrv = eb32_entry(prev, struct tree_occ, node)->server;
dp = hash - prev->key;
dn = next->key - hash;
if (dp <= dn) {
next = prev;
nsrv = psrv;
}
while (p->lbprm.chash.balance_factor && !chash_server_is_eligible(nsrv)) {
next = eb32_next(next);
if (!next)
next = eb32_first(root);
nsrv = eb32_entry(next, struct tree_occ, node)->server;
}
return nsrv;
Everything above “HERE” is pre-existing code.
Eligibility test
int chash_server_is_eligible(struct server *s) {
unsigned tot_slots = ((s->proxy->served + 1) * s->proxy->lbprm.chash.balance_factor + 99) / 100;
unsigned slots_per_weight = tot_slots / s->proxy->lbprm.tot_weight;
unsigned remainder = tot_slots % s->proxy->lbprm.tot_weight;
unsigned slots = s->eweight * slots_per_weight;
slots += ((s->cumulative_weight + s->eweight) * remainder) / s->proxy->lbprm.tot_weight
- (s->cumulative_weight * remainder) / s->proxy->lbprm.tot_weight;
if (slots == 0)
slots = 1;
return s->served < slots;
}
Timeline
- 2016/09/07 - First experimental patch submitted
- Very encouraging and helpful response
- 2016/09/20 - Bugfixes, configurability, weighting support
- 2016/10/25 - Final tweaks and documentation
- 2016/10/26 - Put into production at Vimeo
- 2016/11/25 - HAProxy 1.7.0 stable release includes bounded-load consistent hashing
- 2017/04/18 - Meeting and Presentation at Google NYC
Willy was very enthusiastic about the feature and very helpful in getting my work
up to snuff. The only delay was one of those long European vacations in the middle :)
The researchers who wrote the paper were very happy to see their work used in real life –
and outside of Google!
Cache Hit %
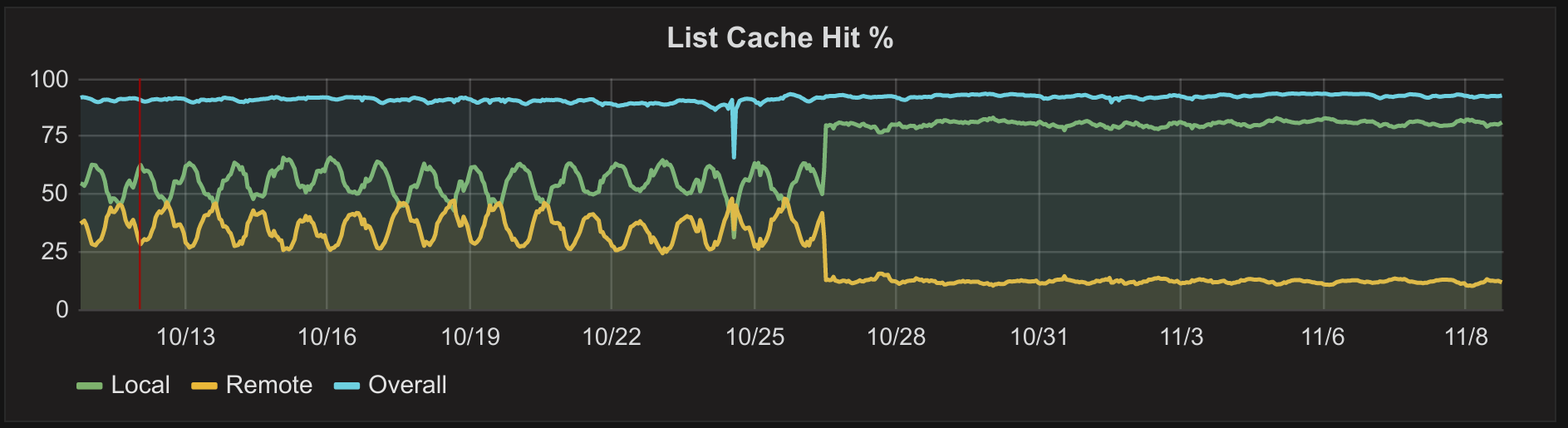
The ripples are diurnal variation caused by scaling the number of servers with load. Here you see the effect:
more servers = less local hits, more traffic to the shared cache.
Shared Cache Bandwidth
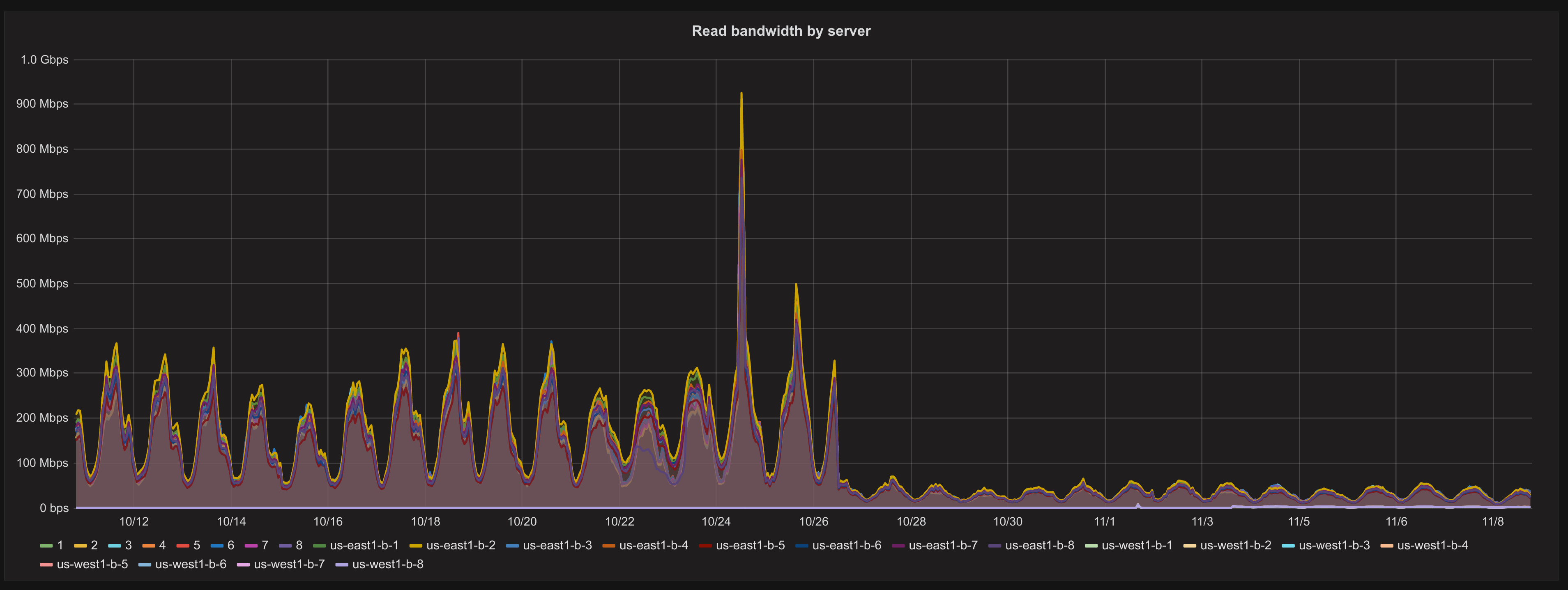
Response Time
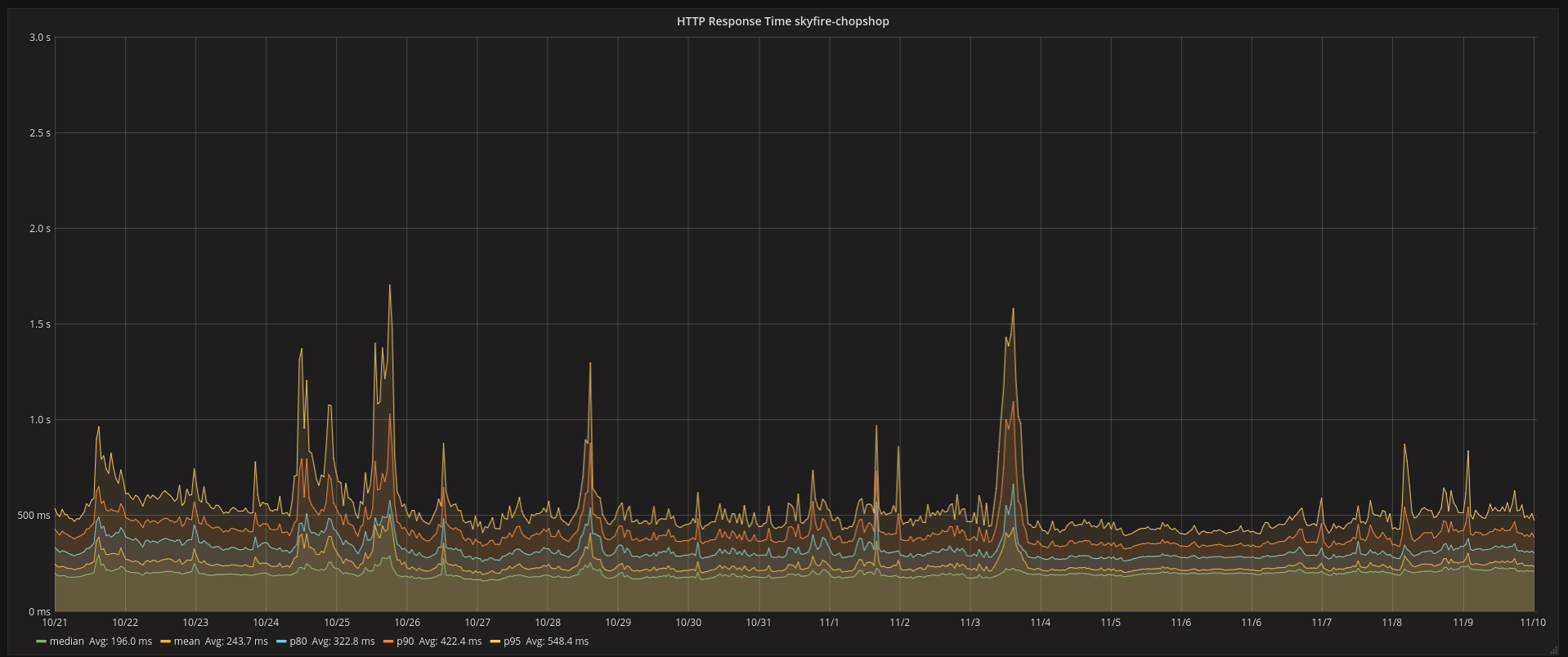
i.e. no difference. Switching to consistent hashing made things no worse at our current traffic, which is all I could
ask for.
Nice Properties
- Servers can’t get overloaded by more than a configurable factor
- As long as servers aren’t overloaded, it’s the same as consistent hashing
- Local cache handles most requests, so the shared cache is less of a bottleneck
- When traffic spills over from a busy server:
- Usually the same for the same content (good for caching popular content)
- Usually different for different content (good for distributing load among servers)
- Scalability and reliability are both less uncertain in the future
Closing Notes
- Finding a research paper that was practical enough to implement, but not alredy implemented, was a stroke of luck.
- Another kind of cache locality to think about.
I’m not a keynote speaker here to make inspirational pronouncements about the future, so I’ll keep it simple.
Usually when I encounter research algorithms, either they’ve already been implemented, or else they’re
so abstruse that maybe I can appreciate them, but I have no chance of doing anything with them. I think
I was very lucky to find a paper - that was not only applicable, but also well within my reach. But somebody
has to do it, so keep your eyes open.
Data organization for cacheline locality, CPU pinning for L2 cache locality… smart load balancing for
memcache locality! Sometimes the cloud really deserves to be thought of as a distributed system, and optimized
for.
